![]()
Model evaluation#
After you’ve trained several models, you may want to generate some accuracy metrics to compare between them. This notebook demonstrates how you’ll do that given a trained model.
Let’s start by installing SLEAP and downloading the trained model.
!pip uninstall -qqq -y opencv-python opencv-contrib-python
!pip install -qqq "sleap[pypi]>=1.3.3"
!apt -qq install tree
!wget -q https://storage.googleapis.com/sleap-data/reference/flies13/td_fast.210505_012601.centered_instance.n%3D1800.zip
!unzip -qq -o -d "td_fast.210505_012601.centered_instance.n=1800" "td_fast.210505_012601.centered_instance.n=1800.zip"
E: Could not open lock file /var/lib/dpkg/lock-frontend - open (13: Permission denied)
E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), are you root?
A trained SLEAP model will be a folder containing files that specify metadata that is useful for evaluation and analysis. The exact set of files may depend on the configuration, but all models will come with:
metrics.train.npz: Metrics for the training split.metrics.val.npz: Metrics for the validation split. This is what you’ll want to use most of the time since it wasn’t directly used for optimizing the model.
Note: A test split will also be evaluated if it was provided during training and saved to metrics.test.npz.
!tree td_fast.210505_012601.centered_instance.n=1800
td_fast.210505_012601.centered_instance.n=1800
├── best_model.h5
├── initial_config.json
├── labels_gt.test.slp
├── labels_gt.train.slp
├── labels_gt.val.slp
├── labels_pr.test.slp
├── labels_pr.train.slp
├── labels_pr.val.slp
├── labels_pr.with_centroid.test.slp
├── metrics.test.npz
├── metrics.train.npz
├── metrics.val.npz
├── metrics.with_centroid.test.npz
├── model_info.json
├── training_config.json
└── training_log.csv
0 directories, 16 files
Additionally, the following files are included and may also be useful:
best_model.h5: The actual saved model and weights. This can be loaded withtf.keras.model.load_model()but it is recommended to usesleap.load_model()instead as it takes care of adding some additional inference-only procedures.training_config.json: The configuration for the model training job, including metadata inferred during the training procedure. It can be loaded withsleap.load_config().labels_gt.train.slpandlabels_pr.train.slp: These are SLEAP labels files containing the ground truth and predicted points for the training split. They do not contain the images, but can be used to retrieve the poses used.labels_gt.val.slpandlabels_pr.val.slp: These are SLEAP labels files containing the ground truth and predicted points for the validation split. They do not contain the images, but can be used to retrieve the poses used.
import sleap
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
mpl.style.use("seaborn-deep")
sleap.versions()
2023-09-01 14:13:14.982109: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:13:14.982120: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
SLEAP: 1.3.1
TensorFlow: 2.8.4
Numpy: 1.21.6
Python: 3.7.12
OS: Linux-5.15.0-78-generic-x86_64-with-debian-bookworm-sid
SLEAP metrics can be loaded using the sleap.load_metrics() API:
help(sleap.load_metrics)
Help on function load_metrics in module sleap.nn.evals:
load_metrics(model_path: str, split: str = 'val') -> typing.Dict[str, typing.Any]
Load metrics for a model.
Args:
model_path: Path to a model folder or metrics file (.npz).
split: Name of the split to load the metrics for. Must be `"train"`, `"val"` or
`"test"` (default: `"val"`). Ignored if a path to a metrics NPZ file is
provided.
Returns:
The loaded metrics as a dictionary with keys:
- `"vis.tp"`: Visibility - True Positives
- `"vis.fp"`: Visibility - False Positives
- `"vis.tn"`: Visibility - True Negatives
- `"vis.fn"`: Visibility - False Negatives
- `"vis.precision"`: Visibility - Precision
- `"vis.recall"`: Visibility - Recall
- `"dist.avg"`: Average Distance (ground truth vs prediction)
- `"dist.p50"`: Distance for 50th percentile
- `"dist.p75"`: Distance for 75th percentile
- `"dist.p90"`: Distance for 90th percentile
- `"dist.p95"`: Distance for 95th percentile
- `"dist.p99"`: Distance for 99th percentile
- `"dist.dists"`: All distances
- `"pck.mPCK"`: Mean Percentage of Correct Keypoints (PCK)
- `"oks.mOKS"`: Mean Object Keypoint Similarity (OKS)
- `"oks_voc.mAP"`: VOC with OKS scores - mean Average Precision (mAP)
- `"oks_voc.mAR"`: VOC with OKS scores - mean Average Recall (mAR)
- `"pck_voc.mAP"`: VOC with PCK scores - mean Average Precision (mAP)
- `"pck_voc.mAR"`: VOC with PCK scores - mean Average Recall (mAR)
Loading the metrics for the validation split of the model we can see all of the available keys:
metrics = sleap.load_metrics("td_fast.210505_012601.centered_instance.n=1800", split="val")
print("\n".join(metrics.keys()))
vis.tp
vis.fp
vis.tn
vis.fn
vis.precision
vis.recall
dist.dists
dist.avg
dist.p50
dist.p75
dist.p90
dist.p95
dist.p99
pck.thresholds
pck.pcks
pck.mPCK_parts
pck.mPCK
oks.mOKS
oks_voc.match_score_thresholds
oks_voc.recall_thresholds
oks_voc.match_scores
oks_voc.precisions
oks_voc.recalls
oks_voc.AP
oks_voc.AR
oks_voc.mAP
oks_voc.mAR
pck_voc.match_score_thresholds
pck_voc.recall_thresholds
pck_voc.match_scores
pck_voc.precisions
pck_voc.recalls
pck_voc.AP
pck_voc.AR
pck_voc.mAP
pck_voc.mAR
To start, let’s look at the summary of the localization errors:
print("Error distance (50%):", metrics["dist.p50"])
print("Error distance (90%):", metrics["dist.p90"])
print("Error distance (95%):", metrics["dist.p95"])
Error distance (50%): 0.9010142093245521
Error distance (90%): 2.0545800141197903
Error distance (95%): 3.0166608700891056
These are the percentiles of the distribution of how far off the model was from the ground truth location.
We can visualize the entire distribution like this:
plt.figure(figsize=(6, 3), dpi=150, facecolor="w")
sns.histplot(metrics["dist.dists"].flatten(), binrange=(0, 20), kde=True, kde_kws={"clip": (0, 20)}, stat="probability")
plt.xlabel("Localization error (px)");
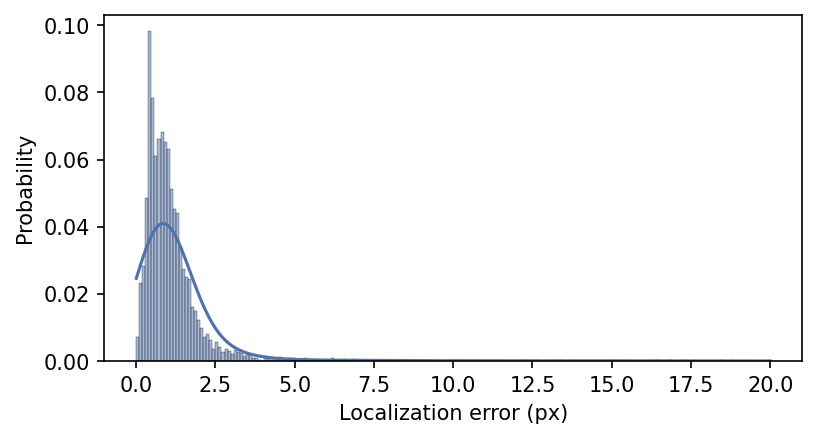
This metric is intuitive, but it does not incorporate other sources of error like those stemming from poor instance detection and grouping, or missing points.
The Object Keypoint Similarity (OKS) is a more holistic metric that takes factors such as landmark visibility, animal size, and the difficulty in locating keypoints (all are assumed to be “easy” for our calculations). You can read more about this and other pose estimation metrics in: https://arxiv.org/abs/1707.05388
First let’s plot the distribution of OKS scores:
plt.figure(figsize=(6, 3), dpi=150, facecolor="w")
sns.histplot(metrics["oks_voc.match_scores"].flatten(), binrange=(0, 1), kde=True, kde_kws={"clip": (0, 1)}, stat="probability")
plt.xlabel("Object Keypoint Similarity");
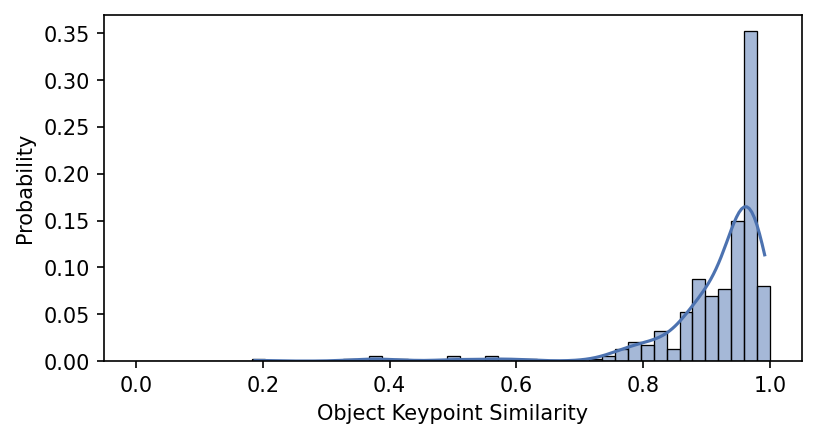
Since these range from 0 to 1, it seems like we’re doing pretty well!
Another way to summarize this is through precision-recall curves, which evaluate how well the model does at different thresholds of OKS scores. The higher the threshold, the more stringent our criteria for classifying a prediction as correct.
Here we plot this at different thresholds:
plt.figure(figsize=(4, 4), dpi=150, facecolor="w")
for precision, thresh in zip(metrics["oks_voc.precisions"][::2], metrics["oks_voc.match_score_thresholds"][::2]):
plt.plot(metrics["oks_voc.recall_thresholds"], precision, "-", label=f"OKS @ {thresh:.2f}")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.legend(loc="lower left");
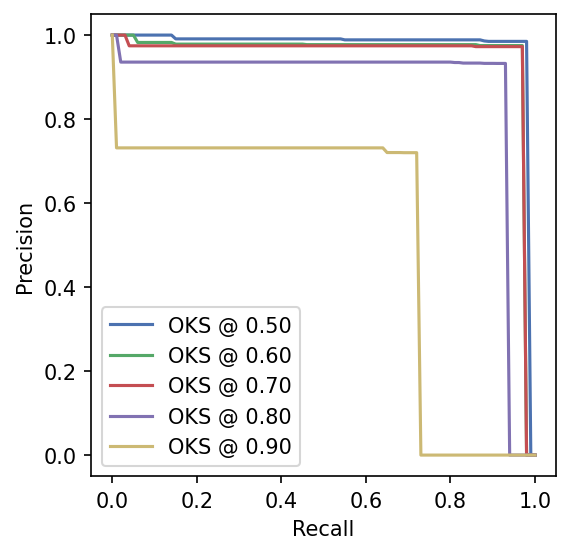
An easy way to summarize this analysis is to take the average over all of these thresholds to compute the mean Average Precision (mAP) and mean Average Recall (mAR) which are widely used in the pose estimation literature.
Here are those values saved out:
print("mAP:", metrics["oks_voc.mAP"])
print("mAR:", metrics["oks_voc.mAR"])
mAP: 0.8150621709973537
mAR: 0.8885
Great, but what if we have some new labels or want to evaluate the model with an updated set of labels for better comparisons with newer models?
For this, we’ll need to generate new predictions.
First, let’s download a new SLEAP labels package file (.pkg.slp). This is important since it denotes that the labels contain the images as well which we need for predicting.
!wget -q https://storage.googleapis.com/sleap-data/datasets/wt_gold.13pt/tracking_split2/test.pkg.slp
Next we can simply load the model, the ground truth (GT) labels, and generate the predictions (~1 min on CPU):
predictor = sleap.load_model("td_fast.210505_012601.centered_instance.n=1800")
labels_gt = sleap.load_file("test.pkg.slp")
labels_pr = predictor.predict(labels_gt)
2023-09-01 14:14:04.208933: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-09-01 14:14:04.209734: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209771: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcublas.so.11'; dlerror: libcublas.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209801: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcublasLt.so.11'; dlerror: libcublasLt.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209829: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcufft.so.10'; dlerror: libcufft.so.10: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209859: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcurand.so.10'; dlerror: libcurand.so.10: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209886: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcusolver.so.11'; dlerror: libcusolver.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209912: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcusparse.so.11'; dlerror: libcusparse.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209939: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/talmolab/micromamba/envs/sleap_jupyter/lib/python3.7/site-packages/cv2/../../lib64:
2023-09-01 14:14:04.209945: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1850] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2023-09-01 14:14:04.245745: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-09-01 14:14:07.317060: W tensorflow/core/grappler/costs/op_level_cost_estimator.cc:690] Error in PredictCost() for the op: op: "CropAndResize" attr { key: "T" value { type: DT_UINT8 } } attr { key: "extrapolation_value" value { f: 0 } } attr { key: "method" value { s: "bilinear" } } inputs { dtype: DT_UINT8 shape { dim { size: 4 } dim { size: 1024 } dim { size: 1024 } dim { size: 1 } } } inputs { dtype: DT_FLOAT shape { dim { size: -2 } dim { size: 4 } } } inputs { dtype: DT_INT32 shape { dim { size: -2 } } } inputs { dtype: DT_INT32 shape { dim { size: 2 } } } device { type: "CPU" vendor: "GenuineIntel" model: "103" frequency: 3600 num_cores: 16 environment { key: "cpu_instruction_set" value: "AVX SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2" } environment { key: "eigen" value: "3.4.90" } l1_cache_size: 49152 l2_cache_size: 524288 l3_cache_size: 16777216 memory_size: 268435456 } outputs { dtype: DT_FLOAT shape { dim { size: -2 } dim { size: -27 } dim { size: -28 } dim { size: 1 } } }
2023-09-01 14:14:07.320224: W tensorflow/core/grappler/costs/op_level_cost_estimator.cc:690] Error in PredictCost() for the op: op: "CropAndResize" attr { key: "T" value { type: DT_FLOAT } } attr { key: "extrapolation_value" value { f: 0 } } attr { key: "method" value { s: "bilinear" } } inputs { dtype: DT_FLOAT shape { dim { size: -42 } dim { size: -43 } dim { size: -44 } dim { size: 1 } } } inputs { dtype: DT_FLOAT shape { dim { size: -10 } dim { size: 4 } } } inputs { dtype: DT_INT32 shape { dim { size: -10 } } } inputs { dtype: DT_INT32 shape { dim { size: 2 } } } device { type: "CPU" vendor: "GenuineIntel" model: "103" frequency: 3600 num_cores: 16 environment { key: "cpu_instruction_set" value: "AVX SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2" } environment { key: "eigen" value: "3.4.90" } l1_cache_size: 49152 l2_cache_size: 524288 l3_cache_size: 16777216 memory_size: 268435456 } outputs { dtype: DT_FLOAT shape { dim { size: -10 } dim { size: -48 } dim { size: -49 } dim { size: 1 } } }
Generating another set of metrics can then be calculated with the pair of GT and predicted labels:
metrics = sleap.nn.evals.evaluate(labels_gt, labels_pr)
print("Error distance (50%):", metrics["dist.p50"])
print("Error distance (90%):", metrics["dist.p90"])
print("Error distance (95%):", metrics["dist.p95"])
print("mAP:", metrics["oks_voc.mAP"])
print("mAR:", metrics["oks_voc.mAR"])
Error distance (50%): 0.8984147543126978
Error distance (90%): 2.197896466395166
Error distance (95%): 3.1484228079076315
mAP: 0.797836431061851
mAR: 0.8782499999999999